隨著企業數據量的激增和業務場景的復雜化,傳統集中式存儲已難以滿足高并發、高可用、跨地域的數據處理需求。基于GridFS的異地分布式存儲架構,為構建現代化數據中臺和彈性可擴展的數據處理服務提供了強有力的技術支撐。本文旨在探討如何利用這一架構構建高效、可靠的數據中臺體系。
一、 GridFS:分布式文件存儲的基石
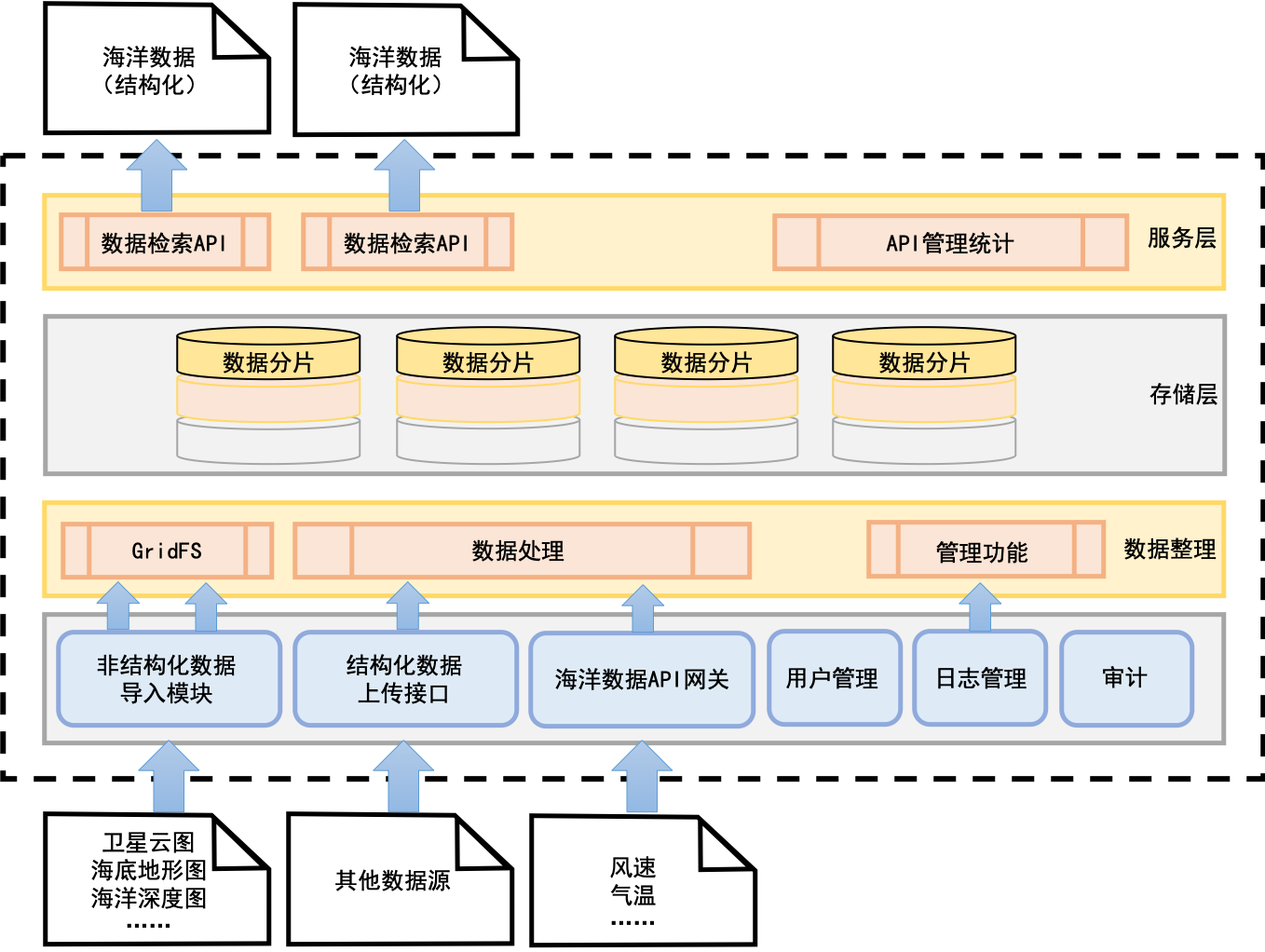
GridFS是MongoDB用于存儲和檢索超出16MB文檔大小限制文件的一種規范。它將大文件分割成多個塊(chunks),并將這些塊作為獨立的文檔存儲在集合中,同時將文件的元數據存儲在另一個集合中。這種設計使其天然支持分布式存儲:
- 分片與負載均衡:文件塊可以分布在不同分片(shard)上,實現數據的水平擴展與負載均衡。
- 高可用性:通過副本集(Replica Set)機制,確保每個數據塊都有多個副本,即便個別節點故障,數據依然可用。
- 地理位置感知:MongoDB的分片集群可以配置為感知數據中心或區域,將數據塊存儲在最靠近用戶的副本上,從而降低訪問延遲。
二、 構建異地分布式存儲架構
構建基于GridFS的異地分布式存儲,核心在于利用MongoDB分片集群的跨地域部署能力:
- 多數據中心部署:在北京、上海、深圳等業務熱點區域部署分片集群的節點(包括配置服務器、分片節點和路由節點)。
- 分片策略配置:
- 基于哈希的分片:將文件塊的_id進行哈希,均勻分布到各個分片,適用于無明確地理偏好的海量文件存儲。
- 基于范圍的分片(結合標簽感知):為不同數據中心的分片打上標簽(如
zone: 'bj'),并結合文件元數據(如uploadRegion)進行范圍分片,確保特定區域生成的文件主要存儲在該區域的分片上,實現“數據就近存儲”。
- 讀寫關注與一致性:通過設置適當的讀寫關注(Read Concern)和寫確認(Write Concern),在跨地域場景下平衡數據一致性、可用性和延遲。例如,對于本地讀操作,可設置
local讀關注以獲取最低延遲;對于關鍵寫入,可設置majority寫確認以確保數據持久化。
三、 數據中臺:統一的數據資產與管理層
基于上述分布式存儲,數據中臺扮演著“數據資產化與管理中樞”的角色:
- 統一元數據管理:擴展GridFS的元數據集合,納入業務標簽、數據血緣、訪問權限、生命周期策略等信息,形成統一的數據資產目錄。
- 標準化數據接入與服務:提供統一的API網關和SDK,封裝底層存儲的復雜性。所有業務系統通過標準接口上傳、查詢、下載文件,實現數據的“一點接入,全局共享”。
- 數據治理與安全:在接入層實施數據加密(客戶端或服務端加密)、訪問控制(基于角色的權限管理)與審計日志,確保數據安全合規。結合生命周期管理策略,自動將冷數據歸檔至成本更低的存儲層。
四、 彈性可擴展的數據處理服務
數據處理服務構建于數據中臺之上,利用分布式存儲的特性實現高效計算:
- 微服務化架構:將圖片處理、視頻轉碼、文檔解析、大數據分析等處理功能拆分為獨立的微服務。每個服務無狀態,可獨立水平擴展。
- 事件驅動與流處理:當文件通過數據中臺API上傳后,可自動發布一個包含文件元數據的事件(如到Kafka)。數據處理服務訂閱相關事件,觸發對應的處理流水線(如上傳圖片后自動生成縮略圖)。
- 就近計算與緩存:結合“數據就近存儲”的優勢,調度處理任務到文件所在區域的數據中心進行計算,大幅減少數據傳輸開銷。頻繁訪問的中間或結果數據可存入Redis等分布式緩存,加速后續訪問。
- 工作流編排:對于復雜的數據處理任務(如ETL流水線),使用工作流引擎(如Apache Airflow)進行編排,可視化地管理任務依賴、重試與監控。
五、 優勢與挑戰
核心優勢:
無限擴展性:存儲與計算能力均可通過增加分片和服務實例線性擴展。
全局低延遲:數據就近存儲與計算,優化了用戶體驗。
高可用與容災:多副本跨地域分布,具備天然的容災能力。
技術棧統一:文檔數據(元數據)與文件數據使用同一數據庫(MongoDB),簡化了技術架構。
面臨的挑戰與考量:
跨地域一致性:需要根據業務容忍度仔細設計一致性模型。
運營成本:多數據中心的基礎設施與網絡成本較高。
架構復雜性:分片集群的部署、監控與運維需要較高的專業能力。
生態工具:相較于HDFS、對象存儲(S3),GridFS在大數據生態(如直接與Spark、Hive集成)中的工具支持相對較少,可能需要額外的適配開發。
基于GridFS構建異地分布式存儲,是打造面向海量非結構化數據、具備全局服務能力的數據中臺的一種有效實踐。它通過將分布式數據庫的彈性、擴展性與文件存儲需求深度融合,為上層多樣化的數據處理服務提供了堅實、靈活的數據底座。成功的關鍵在于根據具體的業務場景、成本預算和技術實力,審慎設計分片策略、數據一致性模型和微服務架構,并配以完善的監控與運維體系。